So I have been getting alerts from goldengate that some processes have had lag
at checkpoint as unknown status for both extract and replicat. This was not on any
one specific extract or replicat this behavior was for all the processes back and forth.
But there was no actual lag, it was false alerting.
at checkpoint as unknown status for both extract and replicat. This was not on any
one specific extract or replicat this behavior was for all the processes back and forth.
But there was no actual lag, it was false alerting.
GGSCI (node1.com) 1>
Program Status Group Lag at Chkpt Time Since Chkpt
MANAGER RUNNING
EXTRACT RUNNING EXCFAE2 unknown 00:00:02
REPLICAT RUNNING RPCFAE2 00:00:00 00:00:08
For Replicat, lag is the difference, in seconds, between the time that the last record was
processed by Replicat, based on the system clock and the timestamp of the record in the
trail.
For an extract Lag at checkpoint in Oracle GoldenGate shows the difference between the
time when the record was processed by the extract and the timestamp of that record in the
database.
The processing time is based on the operating system clock running Oracle GoldenGate.
The time of the record in the database is based on the database clock. If the value is shown
as unknown, there could be several reasons:
1. A restart is required for the processes.
2. Database time has a mismatch with operating system.
3.Goldengate home has the mismatch with database time.
4. Goldengate home has a mismatch with operating system.
5. Or if RAC then multiple servers in the cluster might have a mismatch of time if not time zone.
1. A restart is required for the processes.
2. Database time has a mismatch with operating system.
3.Goldengate home has the mismatch with database time.
4. Goldengate home has a mismatch with operating system.
5. Or if RAC then multiple servers in the cluster might have a mismatch of time if not time zone.
Troubleshooting:
So I was not sure which one of the reasons was causing it and so i verified all the above.
1. The processes were restarted including the manager.
1. The processes were restarted including the manager.
Stopped all the processes and restarted.
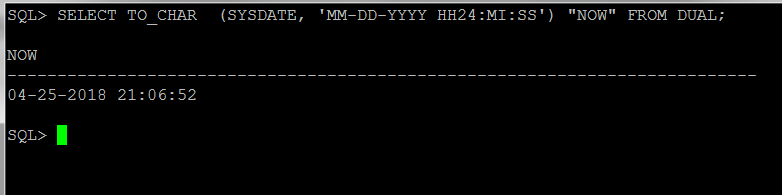
2. Database time did not have a mismatch with operating system.
SQL> SELECT TO_CHAR (SYSDATE, 'MM-DD-YYYY HH24:MI:SS') "NOW" FROM DUAL;
NOW
---------------------------------------------------------------------------
04-25-2018 21:03:59
SQL> !date
Wed Apr 25 21:04:04 GMT 2018
|
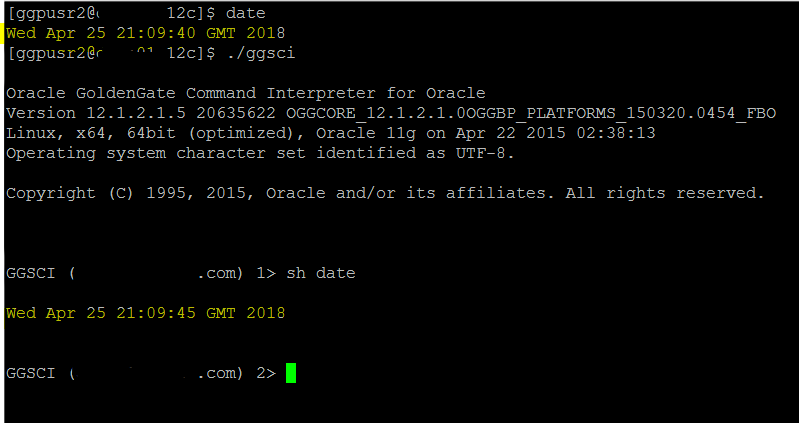
3. GG home did not had a mismatch in time with the database.

4. GG home did not had mismatch with the OS time where it was installed.
NOTE:The difference in seconds is the diff of me getting in ggsci and executing the command.
NOTE:The difference in seconds is the diff of me getting in ggsci and executing the command.
5. So the database, goldengate home and operating system all are in sync but we need to
make sure all nodes on all the RAC nodes are also in sync. That's where the problem existed,
I ran the dcli command, so i don't have to do it on multiple servers. You can check date individually
on all nodes and compare as well. I found out two of my nodes are out of sync.
[root@dg01 ~]# dcli -l root -g dbs_group "date"
dg01: Wed Apr 25 17:51:19 GMT 2018
dg02: Wed Apr 25 17:51:19 GMT 2018
dg03: Wed Apr 25 17:52:51 GMT 2018
dg04: Wed Apr 25 17:52:51 GMT 2018
dg05: Wed Apr 25 17:51:19 GMT 2018
dg06: Wed Apr 25 17:51:19 GMT 2018
dg07: Wed Apr 25 17:51:19 GMT 2018
dg08: Wed Apr 25 17:51:19 GMT 2018
|
Solution:
Sync the ntp server date with other nodes.
1. Find the name of the ntp server and check if its running.
Sync the ntp server date with other nodes.
1. Find the name of the ntp server and check if its running.
[root@dg03 ~]# ntpq -p
remote refid st t when poll reach delay offset jitter
==========================================
ntpdg.com LOCAL(0) 3 u 3 16 377 0.595 -0.004 2.360
[root@dg03 ~]# /sbin/service ntpd status
ntpd (pid 21394) is running...
Same thing for node 4:
[root@dg04 ~]# ntpq -p
remote refid st t when poll reach delay offset jitter
==========================================
ntpdg.com LOCAL(0) 3 u 3 16 377 0.595 -0.004 2.360
[root@dg04~]# /sbin/service ntpd status
ntpd (pid 21394) is running...
|
ntpdg.com ⇒ is my ntp server and it is running.
2. Now we know which servers are not in sync to which ntp server. Also that since the ntp
is already running we have to forcefully let the node sync up using -u command. Lets run the
sync command
[root@dg03 ~]# ntpdate -u ntpdg.com
[root@dg04 ~]# ntpdate -u ntpdg.com
Now check the date for all the nodes and compare:I see all are in sync.
[root@dg01 ~]# dcli -l root -g dbs_group "date"
dg01: Wed Apr 25 19:51:00 GMT 2018
dg02: Wed Apr 25 19:51:00 GMT 2018
dg03: Wed Apr 25 19:51:00 GMT 2018
dg04: Wed Apr 25 19:51:00 GMT 2018
dg05: Wed Apr 25 19:51:00 GMT 2018
dg06: Wed Apr 25 19:51:00 GMT 2018
dg07: Wed Apr 25 19:51:00 GMT 2018
dg08: Wed Apr 25 19:51:00 GMT 2018
|
3. Give it 10-15 min and lets check GG processes now again and see if there is any unknown lag
at checkpoint.
GGSCI (dg01.com) 2> info all
Program Status Group Lag at Chkpt Time Since Chkpt
MANAGER RUNNING
EXTRACT RUNNING EXCFAE1 00:00:03 00:00:10
REPLICAT RUNNING RPCFAE1 00:00:00 00:00:02
|
That is it you resolved the unknown lag at checkpoint.
No comments:
Post a Comment